服务咨询
全天高效服务

- Tel:13533491614
跨云的快速、高可用性、弹性和可扩展的缓存层
缓存通过将最常用数据的副本存储在临时但非常快速的存储上来提高应用程序响应时间。内存缓存解决方案将工作集保存在高速 DRAM 中,而不是缓慢旋转的磁盘中,可以非常有效地实现这些目标。虽然缓存通常用于改善应用程序延迟,但高可用性和弹性缓存也可以帮助应用程序扩展。将责任从应用程序的主要逻辑卸载到缓存层可以释放计算资源来处理更多传入请求。

存储 DBMS 数据
大多数传统数据库旨在提供强大的功能,而不是大规模的速度。数据库缓存通常用于存储查找表的副本以及对来自 DBMS 的昂贵查询的回复,以提高应用程序的性能并减少数据源的负载。

用户会话数据
缓存用户会话数据是构建可扩展和响应式应用程序不可或缺的一部分。因为每次用户交互都需要访问会话数据,所以将数据保存在缓存中可以加快对应用程序用户的响应时间。在缓存中保存会话数据比在负载均衡器级别保持会话粘性更好,因为缓存允许任何应用服务器处理请求而不会丢失用户状态,而负载均衡器方法有效地强制会话中的所有请求由单个应用服务器处理。

快速访问 API 响应
现代应用程序是使用通过 API 进行通信的松散耦合组件构建的。应用程序组件使用 API 向其他组件发出服务请求,无论是在应用程序本身内部(微服务架构)还是外部(在软件即服务用例中)。将 API 的回复存储在缓存中,即使只是短暂的,也可以通过避免这种进程间通信来提高应用程序性能。

缓存层必须提供的第一个要求是任何负载下的高性能。 研究表明,为了让用户感知“即时”体验,端到端响应时间必须在 100 毫秒以内。简而言之,高性能缓存层必须始终如一地以低延迟提供高吞吐量,以避免成为性能瓶颈。

高性能缓存层应该能够扩展并满足业务增长或突然激增(如情人节、黑色星期五、自然灾害或流行病)产生的需求。此外,应在不导致停机或离线迁移的情况下动态完成可扩展性,而不会增加响应时间。
越来越多的组织正在采用多云策略,无论是避免供应商锁定还是利用各种云提供商的最佳工具。但是,管理一个地理上分布式的缓存系统要更具挑战性,该系统既要保证亚毫秒级的延迟,又要解决跨多个云的数据集冲突。

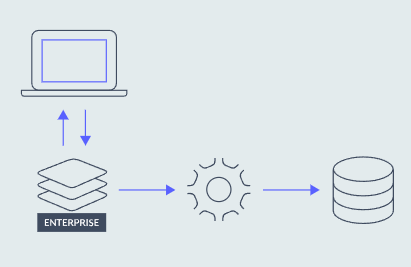
这是使用 Redis 作为缓存的最常见方式。在此策略中,应用程序首先查看缓存以检索数据。如果未找到数据(缓存未命中),则应用程序直接从操作数据存储中检索数据。仅在必要时才将数据加载到缓存中(这就是该方法也称为延迟加载的原因)。读取繁重的应用程序可以极大地受益于实现缓存侧方法。
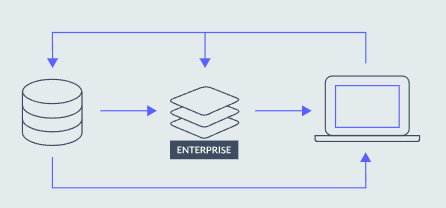
Write-Behind (Write-Back)
在此策略中,数据首先写入缓存(例如 Redis),然后在操作数据存储中异步更新数据。这种方法提高了写入性能并简化了应用程序开发,因为开发人员只写入一个地方(Redis)。RedisGears 提供直写和后写功能。
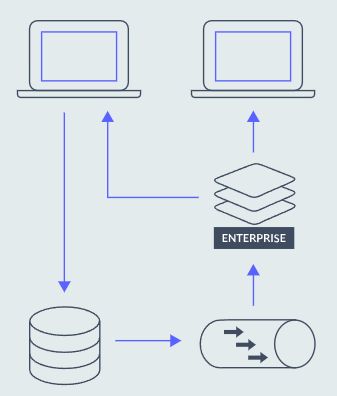
此策略类似于后写方法,因为缓存位于应用程序和操作数据存储之间,但更新是同步完成的。直写模式有利于缓存和数据存储之间的数据一致性,因为写入是在服务器的主线程上完成的。RedisGears 提供直写和后写功能。
只读副本
在您拥有大量历史数据(例如大型机)或要求每次写入都必须记录在可操作数据存储上的环境中,Redis Enterprise 变更数据捕获 (CDC) 连接器可以捕获单个数据更改并传播精确副本不中断正在进行的操作,具有近乎实时的一致性。CDC 与 Redis Enterprise 使用多种数据模型的能力相结合,可以为您提供对以前锁定的数据的宝贵见解。
高可用性、弹性和持久性
应用程序性能依赖于缓存层。由于您的缓存每秒可能会达到数百万次操作,因此即使是一秒钟的停机时间也会对性能和满足您的 SLA 的能力产生极端影响。Redis Enterprise 自动备份、即时故障检测、跨机架/区域/区域的快速恢复以及多个数据持久性选项是确保高可用性缓存层和提供一致用户体验的关键因素。

任何规模的无与伦比的性能
高性能应用程序缓存层需要轻松、即时地扩展以满足增长需求和峰值需求。Redis Enterprise 在亚毫秒级延迟下的高吞吐量、真正的无共享架构以实现线性扩展、支持多租户和多核架构,确保在提供卓越性能的同时充分利用计算资源。
本地延迟的全球分布
无论您的部署环境如何,缓存层都应提供跨地域的高可用性和低延迟。此外,Redis Enterprise 的基于 CRDT 的 Active-Active 技术为读写操作提供本地延迟,为简单和复杂的数据类型提供无缝冲突解决,即使在大量副本关闭时也能确保业务连续性。结果:减少了开发麻烦和操作负担。
开源DNA
有许多可用的解决方案是基于利基技术或为特定用例而构建的,并未被广泛采用。Redis 开源支持 50 多种编程语言、150 多种客户端库和大多数部署环境中的默认缓存层。Redis 是开源 Redis 的故乡,这是连续 4 年最受欢迎的数据库,并将企业级功能带入您的缓存层。

多云或混合部署
开发缓存层应该简单快捷,不会增加团队的运营负担。Redis Enterprise 可以作为完全托管的服务部署在公共云上,让您从配置、修补、监控和其他管理任务中解放出来。它还可以作为软件部署在您自己的基础架构上,让您完全控制管理和配置。此外,支持混合模型以保持操作灵活性。
Redis 是围绕数据结构的概念设计的,可以跨字符串、哈希、排序集、集合、列表、流和其他数据结构或 Redis 模块存储数据集。
使用 Node.js,您可以通过客户端对象的 GET 和 SET 命令从简单字符串中检索和保存键值对,如下所示:

此代码段尝试使用 GET 命令检索与 myStringKey 键关联的字符串值。如果未找到该键,则 SET 命令会存储 myStringKey 的 Redis Enterprise Tutorial 值。可以用 Python 编写相同的代码,如下所示:
