服务咨询
全天高效服务

- Tel:13533491614
“在 Spotify,数据决定一切。”
这一点也不夸张。拥有4.06亿活跃用户和1.8亿付费用户的Spotify仍然是主要的音乐流媒体服务商,这在很大程度上是因为它对用户行为进行了详尽的分析,以便为每位听众提供了个性化的体验。
Spotify的高管喜欢说他们提供了4.06 亿个“单个版本的Spotify,每个版本都包含不同的主页、播放列表和推荐”,而不是单一的平台和UI。
这些个性化推荐和客户体验由Spotify的220多个活跃的ML项目提供支持,所有项目都通过其内部ML网关ML Home运行。这些项目分析用户交互和系统数据,包括超过40亿个用户创建的播放列表、收听历史、喜欢、页面加载时间等。
处理这些数据是一方面。Spotify首先需要可靠地记录、发布和存储所有的这些数据(实际上是600种不同的类型)。这是通过Spotify的事件交付基础架构 (EDI)实现的,该基础架构不断从Spotify用户的应用程序中获取大量的事件数据。根据2021年10月发布的一篇博客文章,EDI每秒可摄取多达800万个事件,平均每天处理5000亿个事件。在存储方面,这相当于每天有70TB的压缩数据(未压缩的350TB)。
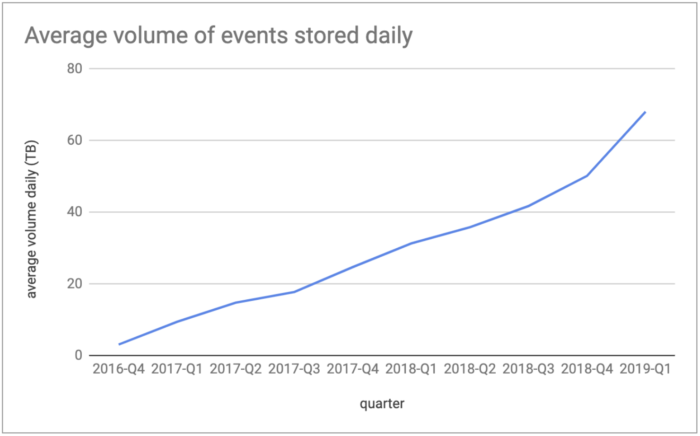
这些统计数据来自2019年第一季度。基于Spotify的持续用户增长,到2022 年,每天摄取的事件数据量可能是今天的两倍甚至三倍。这将转化为每年数十PB的压缩数据。
为了应对这种规模,Spotify 在过去六年中不得不两次升级EDI。
在2016年的第一次升级之前,Spotify的EDI是围绕具有两个主要组件的本地系统构建的:
(1)一个Kafka流处理系统,收集日志并完成推送。
(2)一个Hadoop集群,它使用Hive和Avro格式在HDFS上以一小时的分区存储摄取的事件流 。
2016年之前的EDI版本每秒可以轻松处理多达700,000个事件。除了增长的限制之外,这种基础设施还存在一些问题。首先,数据作业只从每个小时长的分区中读取一次数据。由于网络或软件问题而中断的数据流不会被回填,因为它会为EDI创建太多额外的重新处理以正确存储它。这导致数据不完整和不准确。
其次,EDI是围绕不能持久化或存储事件的旧版Kafka设计的。这意味着事件数据仅在写入Hadoop后才会保留,这使得Hadoop成为所有EDI的单点故障。“如果Hadoop宕机,整个事件传递系统就会停止。” Spotify的工程师写道。
随着事件数量的增加,此类系统停顿和中断也随之增加。为了解决这个问题,Spotify决定将事件交付基础架构迁移到云端——谷歌云。
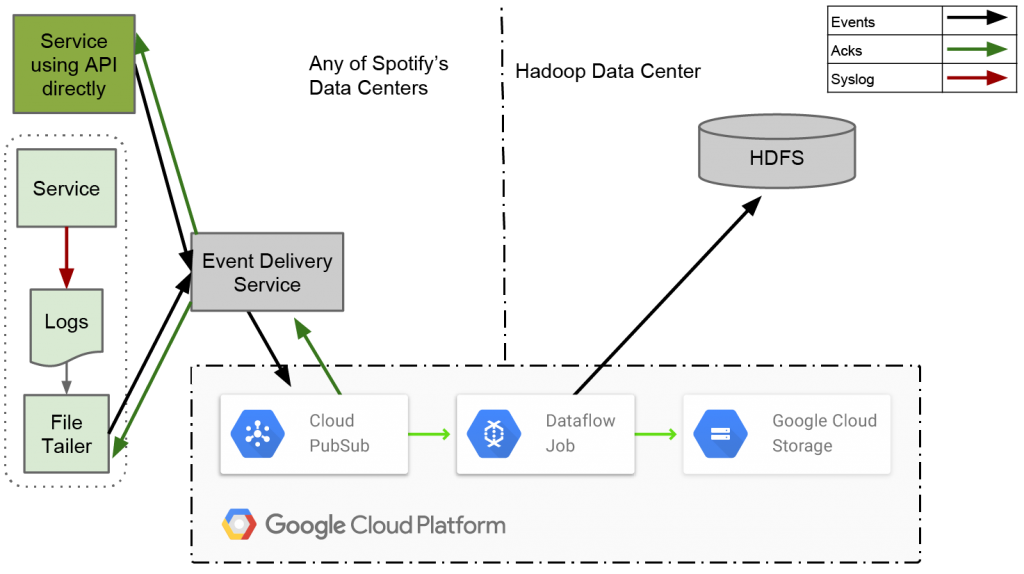
2016年,Spotify通过迁移到Google的托管Hadoop解决方案Dataproc将 Hadoop提升并转移到了Google Cloud Platform (GCP)(上图)。在保留每小时数据分区的同时,Spotify还将Hive和HDFS迁移到BigQuery和Google Cloud Storage。另外,它用Google Pub/Sub取代了Kafka,还添加了Google Compute Engine、CloudSQL、Dataflow 等。
将EDI从Hadoop切换到Google的数据服务堆栈不仅将其规模扩大到每天5 万亿次摄取事件(70 TB 压缩数据),而且“提高了操作稳定性和我们待命的工程师的生活质量”。它还使Spotify的数据符合GDPR。
然而,在接下来的几年时间里,瓶颈慢慢开始出现。即使保留Hadoop的托管版本以及其他一些技术,也很难执行一些升级和满足数据科学家的功能要求。还有一个挥之不去的问题,即数据的不完整和低质量,这降低了Spotify数据社区的生产力。
2019年,Spotify决定硬着头皮打造全新版本的EDI。它在内部构建了一个名为Scio(Apache Beam 的 Scala API)的新数据处理引擎,该引擎在Google Dataflow上运行。Scio随后被Spotify开源,使公司能够大规模运行批量处理和流管道。这打破了对Hadoop和其他遗留技术以及仍在流式传输用户数据的旧版本Spotify应用程序的所有向后兼容性。
另一个重大变化是Spotify用户应用程序重新发送或回填事件数据的新功能。这解决了数据不完整的问题。但是,重新发送的数据可能会产生重复的数据。因此Spotify还引入了事件消息标识符,可以生成查找索引,以便快速找到和删除重复数据。
虽然Spotify将其ML和数据用户迁移到新的EDI平台,但它必须保持旧版本的运行,以保持从未升级的数据源和旧客户端获取数据。Spotify还构建了一个数据转换管道,将旧EDI中的数据导入到新的EDI中。
Spotify没有详细说明在永久关闭旧EDI平台之前构建新版本的EDI、迁移用户和数据源或维护双重基础架构需要多长时间。但它断言整体过渡是有效且没有问题的:
“随着迁移接近尾声,我们几乎抛弃了所有旧的、过时的基础设施,转而采用最先进的技术。我们成功地改变了移动公共汽车的轮子,让Spotify的数据社区一帆风顺。”
数据编排是从不同存储库中获取数据、组合数据然后将数据转换为适合数据仓库、ML模型和其他分析工具的正确格式的过程。
数据编排解决方案,也称为工作流自动化平台,可帮助数据工程师和喜欢 DIY的数据科学家构建、调度和监控数据管道以及工作流。它们使原本暗的数据孤岛具有可见性,标准化不同模式和格式的数据,然后通过数据管道将数据从存储同步到目标数据仓库或分析应用程序。
在前大数据时代,数据转换由ETL数据管道处理,简单的调度通过手动创建的cron作业处理。
随着数据量、数据存储库、数据管道和分析应用程序的爆炸式增长,企业开始寻找更强大的方法来管理其复杂的工作流和数据管道网络。
“数据编排解决方案正在成为数据堆栈的核心部分,”企业技术风险投资家 Astasia Myers在最近的一篇Medium博客文章中写道。
Spotify无疑符合重度数据编排用户的特征。根据Spotify工程博客2022年3 月的一篇文章,Spotify每天运行20,000个批量处理数据管道,这些管道定义在 300多个团队拥有的1,000多个存储库中。
长期以来,这些数据管道中的大多数都使用两种工具进行管理:用于Python 用户的Luigi和用于Java用户的Flo。
Spotify工程师在2010年代初期内部开发了Luigi和Flo,并在几年内将它们都开源了。
使用Luigi和Flo,数据工作流、库和逻辑被打包到Docker映像中,并部署到另一个Spotify构建的开源工具,即数据处理作业调度程序Styx。然后处理数据,然后将其发布到不同的位置。
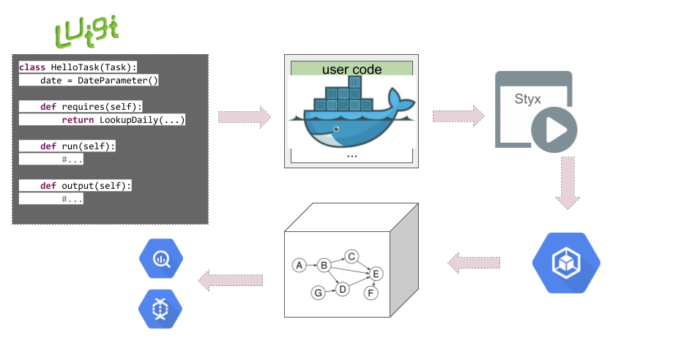
使用Luigi的数据编排工作流程
到2019年,Spotify在Luigi和Flo方面遇到了越来越严重的“问题”。一是维护和更新两个应用程序功能的高维护负担。另一个是无法强制自动升级到最新版本(因为升级是在本地控制的)。最后,工作流容器是“黑匣子”,这意味着无法在数据传输时跟踪数据的进度和健康状况。
Luigi和另一个流行的数据编排解决方案Airflow是“第一代解决方案”,专注于“任务驱动,将任务管理与任务流程解耦”。他们对任务正在处理的数据了解有限。”
Spotify决定需要做出改变。在寻找新的解决方案时,它有两个大目标:
(1)“让升级尽可能顺畅。” Spotify工程师希望自动为用户和存储库安装所有功能和修复程序,以避免必须监控已安装的更新数量或管理零散的版本。
(2)“实现平台自动化功能的开发。” 但由于缺乏对工作流状态的可见性,这是不可能的。
为了实现这一目标,Spotify决定其解决方案需要支持三件事:
(1)在工作流中编排任务的托管服务
(2)解决方案可控的业务逻辑
(3)用户可以使用平台团队分发的SDK定义工作流和任务
Spotify对市场上的数据编排系统进行了广泛比较。最后,它选择使用名为 Flyte的开源工具来构建和管理其数据编排工作流。Flyte于2017年为Lyft内部使用而开发,并于2020年开源。
根据Myers的说法,Flyte等第二代数据编排解决方案“专注于数据驱动,以便他们知道将要转换的数据类型以及如何操作这些数据。他们具有数据意识,可以对数据工件进行测试,并且不仅可以对代码进行版本控制,还可以对工件进行版本控制。”Myers还称赞Flyte共享和编排数据的积极方法,称其与Luigi等第一代系统相比是进步的。她还指出,Flyte有一个成熟的ML编排器,并且是Kubernetes原生的。
据Spotify的工程师称,所有这些都转化为使用Flyte的众多好处,包括:
(1)与Luigi和Flo类似的实体模型和命名法,使用户体验和迁移更容易。
(2)集成Spotify工具的可扩展性
(3)整个平台的维护比我们现有的产品简单得多
(4)可扩展且久经检验
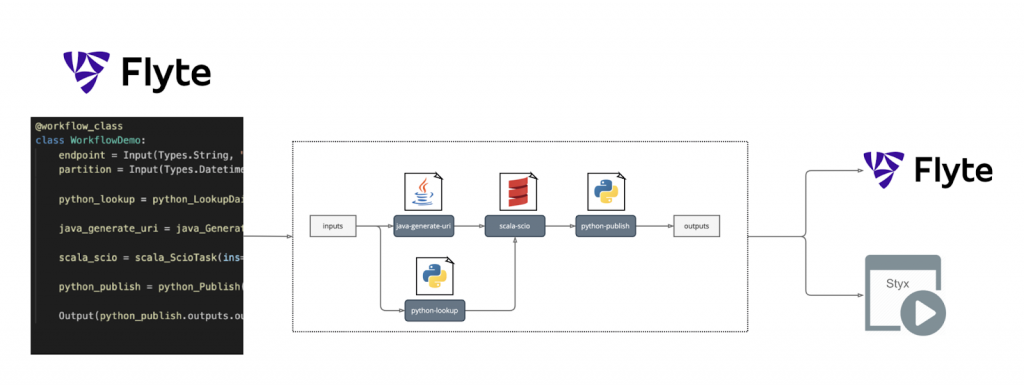
使用Flyte定义数据工作流
虽然这家音乐流媒体公司表示Spotify的Flyte之旅仍在进行中——我们很高兴能够运行关键管道,但我们仍然需要将所有现有管道从Luigi迁移到Flyte。
尽管Spotify很有启发性,但它与大多数企业都有很大不同。
(1)它的工程团队要大得多。
(2)它的IT预算要大得多。
这意味着Spotify拥有资源来获取、部署和定制大量单点解决方案的工程师。
这样的策略不一定对您的企业有意义。
相反,多维数据可观察性数据平台可能是您的数据工程团队获得对数据存储库、工作流和数据管道的可见性和控制、改进向云迁移并优化数据成本的更有效、更强大的方式。
诸如HongKe多维数据可观测平台这样的解决方案使您能够监测和管理您的数据存储库和管道。例如,HongKe Pulse提供计算性能监测和关联,以消除计划外的中断,并通过一次点击来扩展您的工作负载。
HongKe Torch是我们的数据可靠性解决方案,拥有与Hive、HBase、HDFS、Redshift、Azure SQL、Snowflake、Amazon Web Services、Google、Kafka、MySQL、MemSQL、PostgreSQL和Oracle的连接器。这意味着Torch可以自动抓取几乎所有的数据存储库,以便对数据进行分析,验证其质量,并在使用ETL进行传输和转换时,或当你将其从Hadoop转移到现代云数据仓库(如Snowflake)时,对数据进行协调。