服务咨询
全天高效服务

- Tel:13533491614
世界各地的组织正面临着有效分析其指数级增长的数据存储的挑战。今天的企业越来越依赖于利用其不断增长的数据存储来提取对客户行为、安全异常、风险分析、库存和存货预测等方面的可操作的见解。这种向数据驱动方法的转变导致许多企业将其数据存储在大型数据湖中,但他们的分析平台却在不断增长的数据量和速度中挣扎。
BI管道–从数据库基础设施到BI工具–已经变得紧张和缓慢,导致了一些问题。
这些问题背后的罪魁祸首是数据处理和分析技术缺乏进步。在过去的30年里,这个领域的大多数进步都是小规模的创新,集中在优化特定的用例或工作负载大小。由于巨大的数据增长,这些创新,无论是基础设施还是终端用户的BI可视化工具,在短短几年内就会被淘汰或被超越。
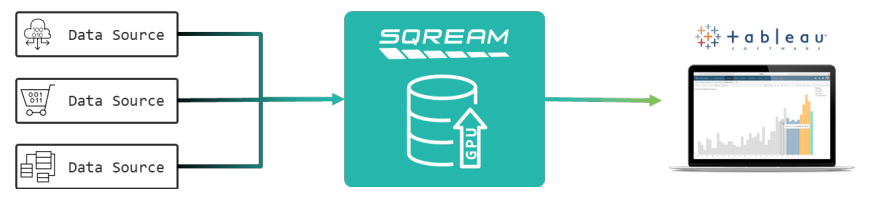
SQream DB带来了一种新的技术方法,从源头上消除了数据专业人员的纠结,从而产生了快速、准确、最新的仪表盘,从中可以提取出大量新的洞察力。SQream的GPU加速数据仓库是为快速、不受限制地访问企业的全部数据而设计的,即使数据呈指数级增长。SQream的技术使Tableau用户能够探索和生产交互式仪表盘,为现代数据驱动的组织的许多方面提供动力。
1.分析时间:数据摄入和准备周期慢
一般来说,数据消费者,特别是数据科学家和商业智能分析师对组织中的数据访问速度越来越感到沮丧。许多分析工作负载需要漫长的摄取过程和数据准备任务,包括关联、预计算、过滤、充实和其他技术。这些数据准备任务通常在非高峰期进行,以避免数据基础设施过载。
不幸的是,这种数据准备严重地限制了分析师进行数据探索的能力。数据的维度通常被降低(例如,总结客户交易,将许多交易折叠成一个),以便以后能够更快地查询。这种在较粗的数据颗粒度和较快的查询之间的权衡,是以使未来的细粒度深入分析成为可能的高代价。
2.数据管道的复杂性性能差,不灵活,难以扩展,最终导致了复杂的解决方案。许多公司现在不仅有数据库管理员,而且还有数据工程师、数据保管员和数据管理员。数据工程师在数据管理方面工作,维护组织的数据基础设施,而数据库管理员现在几乎只关注数据库性能的微调。传统数据仓库的数据库管理员有大量的调整和优化,这些调整和优化是在40多年来对这些解决方案进行修补和解决可扩展性问题的过程中建立起来的。
这些问题会渗透到BI工具和可视化工具中。例如,一个创建新仪表盘的错误尝试可能会产生复杂的查询,从而使数据仓库陷入困境,导致其他业务线的中断。这些中断对基础设施团队和数据消费者来说都是痛苦和合人沮丧的。
然而,由于商业智能分析师是其领域内数据的主宰者,他们是对数据因复杂性、次抽样、不灵活的工具和基础设施而无法访问的业务影响最感到沮丧的人。
3.可扩展性:对不断增长的数据支持不足
传统的数据库,甚至是分布式系统在支持指数级增长的数据量方面都有困难。传统的数据库可能会在数据扩展方面遇到困难,而分布式数据库则可能在运行连接方面遇到困难,而且更难维护。
对于分布式数据系统,性能问题通常是通过增加节点和重新分配数据来处理的。对于传统的数据仓库,解决性能问题的典型方法是购买一个更大的设备,配备更多的内存和CPU。这两种”解决方案”都不是真正的解决方案,而是一个临时的创可贴,直到数据再次增长。
SQream DB是新一代的数据仓库,最大限度地减少了分析时间,消除了复杂的数据管道,并解决了传统解决方案的扩展性差的问题。
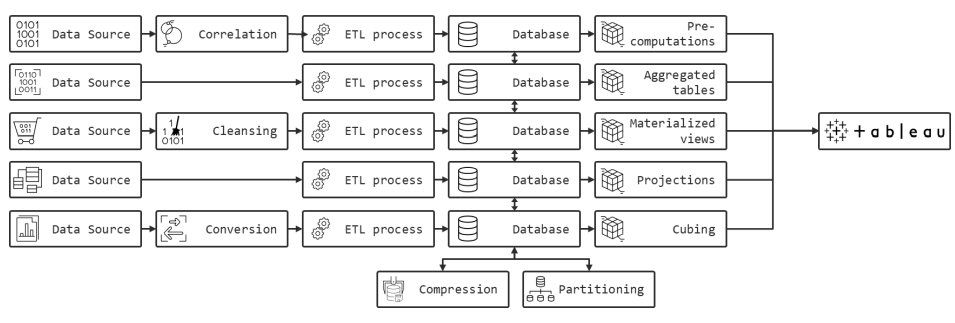
SQream DB的GPU加速架构和自动优化是分析数据的关键因素,无需中间步骤。GPU的原始蛮力允许SQream DB在加载后立即分析数据。这种能力与大多数数据仓库形成鲜明对比,后者需要耗时和限制洞察力的过程,如索引、立方体和投影。在导入过程中,SQream DB自动和透明地准备数据,以便立即进行快速分析–不需要用户干预。

SQream DB表为快速批量摄取进行了优化,加载表的速度超过3TB/小时–只是其他解决方案的一小部分时间。Tableau用户可以利用SQream DB的原始数据为王的方法。由于SQream DB实现了标准的SQL和ODBC连接,用户可以在几秒钟内连接并开始数据探索,而不限制查询的维度或深度。每一列都可以进行连接,不需要索引。
SQream DB为数据仓库带来了一种新的方法。从用户的角度来看,SQream DB看起来像一个标准的分析型SQL数据库,但其底层架构是一个GPU加速的数据仓库,具有高度自动化的”加载和运行”过程,旨在加速和简化数据处理。数据准备工作进一步减少,因为SQream DB在共享数据架构中存储数据,不需要分配密钥或创建预测。
传统的数据仓库依靠一套固定的资源来运行所有的场景。相比之下,SQream DB可以通过结合可用的CPU、GPU、RAM和存储资源,分配额外的资源来处理不同的工作负载。
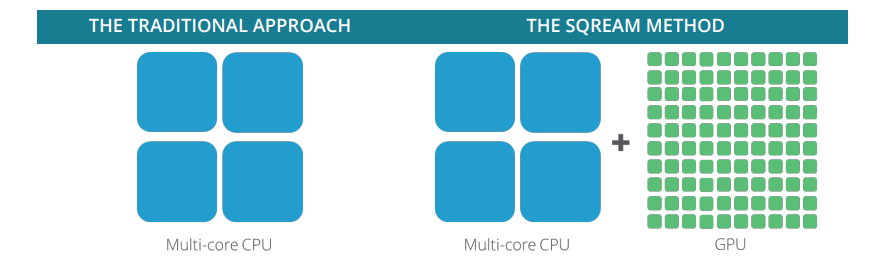
这种CPU和GPU操作的平衡是确保最佳性能的关键。GPU擅长对许多数据流中的大量数据进行重复性操作。其结果是更快的响应时间,即使是在最复杂的仪表盘中。
SQream DB可以扩展到无限的数据大小,许多数据消费者,或两者兼而有之。因为计算是与存储脱钩的,所以扩展只适用于存储,只适用于计算,或两者都适用。这是一个关键因素,为任何规模的组织提供出色的性能,同时减少成本。系统在任何力向的增长都不会影响数据的可用性或完整性,这意味着SQream DB可以扩展到几乎无限的数据规模。

由于其无限的可扩展性,SQream使数据消费者能够分析更多的数据,而不需要投资于复杂的分布式解决方案。SQreamDB通过透明地优化、压缩和分割数据,支持数据消费者和基础设施团队,而不需要干预。

SQream DB的表通过在多个维度上对数据进行超分区来支持可扩展性,这个过程我们称之为分块。分块是在摄入过程中自动和透明地进行的。用户可以查询和互动他们的所有数据,就像一个普通的表。这种能力允许SQream DB表增长到其他数据库无法支持的大小,同时保留了熟悉的管理功能。
由于其Load-and-Go架构的自动化方法、自动适应性压缩和动态工作负载管理(WLM) , SQream DB有助于简化数据架构。与其他数据仓库不同,SQream DB动态响应分析工作负载的变化,自动调整查询和系统资源。压缩是自动的,sQream DB的超分区表也是如此。所有的操作都是通过标准的SQL接口和标准的连接器进行的,具有最大的灵活性。
SQream符合ANSI SQL-92标准,使得与该系统的互动与其他RDBMS没有区别。然而,有了SQream DB,数据专业人员将受益于引擎盖下的许多优势。当在Tableau中通过ODBC发出查询时,SQL命合被立即解析并转换为关系代数,以便在SQream DB查询引擎中进一步处理和优化。
一些最佳实践告诉你,你应该在Tableau中创建一个”提取”,以加快后续处理,防止数据仓库过载。有了SQream DB,提取是过去的事情了。
SQream DB为探索和临时查询进行了优化。查询的相关数据由SQream DB识别,所有关系操作和转换都在GPU上运行。在几秒钟内,产生的数据集以”实时”模式发回给Tableau,确保结果是最新的。
使用SQream DB,不需要预先计算,如创建和管理索引,创建投影或立方体,甚至是物化视图。SQream DB透明地处理查询优化,甚至自动处理负载平衡,因此你可以在”实时”模式下正常使用Tableau。

巧妙的过滤是使SQream DB如此快速的一个主要原因。然而,当你第一次将一组列拖放到工作表中时,Tableau将开始向数据库发出查询。在规模上,当处理数以万亿计的行时,这可能需要一些时间最好的办法是添加数据源过滤器,或者在添加列时暂停工作表,直到你创建了必要的过滤器来限制查询的范围,然后再准备运行它们。有了过滤器,现在可以在几秒钟内访问和分析数万亿的行。
使用内置的Tableau工具来监控查询性能。Tableau包含一个伟大的内置工具,称为性能记录器。许多SQream DB用户将性能记录器与SQream DB自己的日志系统结合使用,以识别较慢的查询并优化性能。

像许多列式数据库一样,SQream DB从只选择相关列。当从一个选择中创建一个组时,确保只选择相关的列。添加额外的列可以增加维度,但会降低性能。
用户使用Tableau的常见挑战大多是由传统的数据管道引起的,这些管道并不是为现代数据规模设计的。SQream DB和Tableau是从你的大数据中获得伟大的可视化分析的理想解决方案。有了SQream DB作为Tableau的分析后端,用户将受益于快速摄取,大幅节省数据准备时间,并在任何规模的数据上获得高性能的可视化分析。