服务咨询
全天高效服务

- Tel:13533491614
问题
远程办公室的用户使用云托管的应用程序会遇到糟糕的应用程序性能。
主张
IT组织认为服务器资源不足。服务器提供商说问题出在客户网络上。双方都没有证据。
所需信息
服务器ping往返时间看起来似乎还可以,至少当工程师在中央办公室偶尔进行测试时看起来还不错。但是此测试仅验证了客户端网络和云环境之间的网络路径。当问题发生时,他们需要数据包级别的详细信息。之所以很难做到这一点,是因为问题并不总是在工程师在现场时就发生的。他们需要一种方法来简单、持续地从客户端捕获信息,以便问题得以解决。
应用程序最近已迁移到云中,因此网络工程团队不再有权访问服务器端进行捕获。
一旦在问题期内正确捕获了问题,就可以测量诸如网络往返时间、服务器响应时间、TCP重传频率和其他TCP离群值之类的统计信息,以隔离真正的问题域(无论是客户端、网络还是云服务器)。
IOTA让事情变得轻松
通过将IOTA串联在客户端网络和边缘路由器之间,这样IT工程师能够在远程站点上实现安装。这个优势使他们能够看到多个客户的活动,而不仅仅是一个。他们可以将问题时期和时间之内的客户活动与良好的性能进行对比。
几个小时后,客户报告说他们再次遇到了性能问题。工程师们可以从中央办公室使用基于Web的界面立即访问IOTA,并开始进行故障排除。几分钟之内,他们就可以访问隔离问题域所需的核心细节。
第1步-确定正确的时间周期
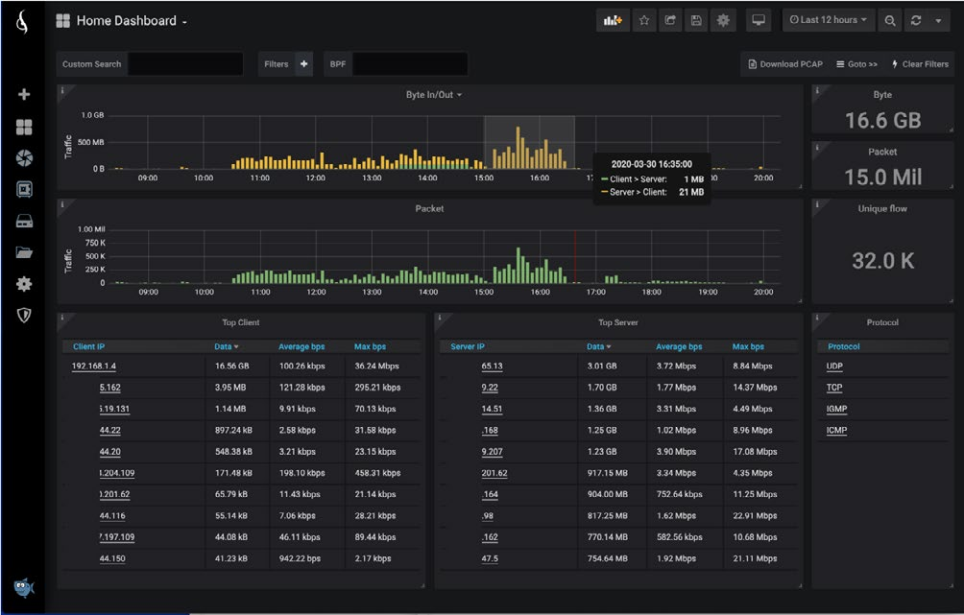
首先,工程师需要过滤问题发生的时间。从主页仪表板的开始屏幕中,他们可以跨越问题发生的时间范围,并查看该时间段内的IP对话。他们观察到了问题客户机和服务器的地址。
第2步-检查服务器响应时间
现在他们有了正确的时间周期,他们需要查看服务器与客户端之间的对话的运行状况。使用UserExperience – Application Latency 仪表板,他们可以测量服务器的应用程序响应时间,无论流量是否加密。他们注意到服务器响应时间的最大延迟为206毫秒。将其与正常的性能时段进行比较,此度量没有显着变化。服务器即使在出现问题期间,也能像往常一样做出响应。
第3步-对TCP进行故障排除
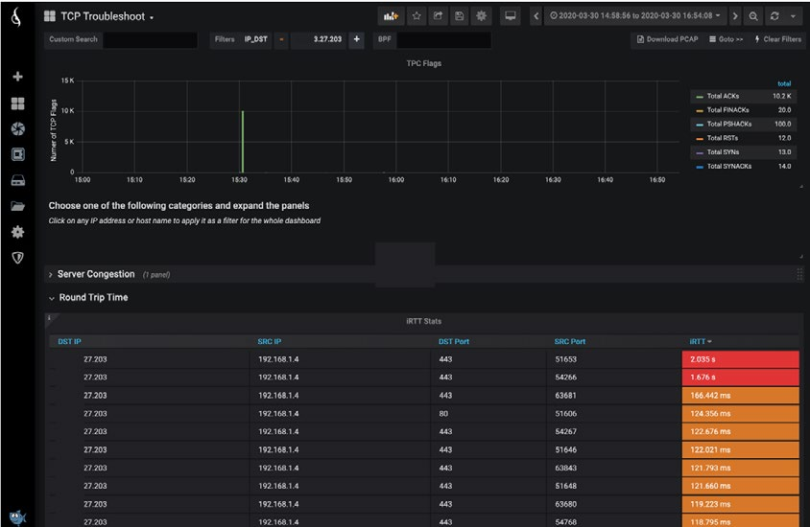
接下来,工程师可以使用“TCP Troubleshoot”仪表板查看流量流本身的运行状况,并设置往返于服务器IP的流量过滤器。
这就是问题所在。在某些时候,客户端和服务器之间的网络往返时间将飙升至超过两整秒!重传统计数据还显示,在此问题期间大量丢失了数据包。
将这些数据与正常性能期间的数据包统计数据进行比较,工程师可以看到,当客户端拥有良好的体验时,网络往返时间很短,并且没有重传。
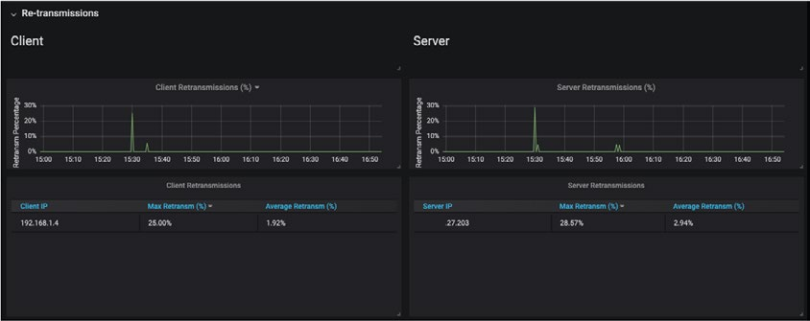
这有助于他们发现,在性能问题期间网络流量下降,并且延迟很高。通常,这是由网络拥塞或错误的链接引起的。
他们还能做些什么来找出根本原因呢?
第4步-检查应用程序带宽
在问题期间,工程师们能够全面调查网络站点的使用情况。通过将带宽仪表板设置为与性能问题相同的时间范围,工程师们能够看到特定应用程序(Microsoft 365)的利用率出现峰值。同样的情况也发生在上一次问题中。
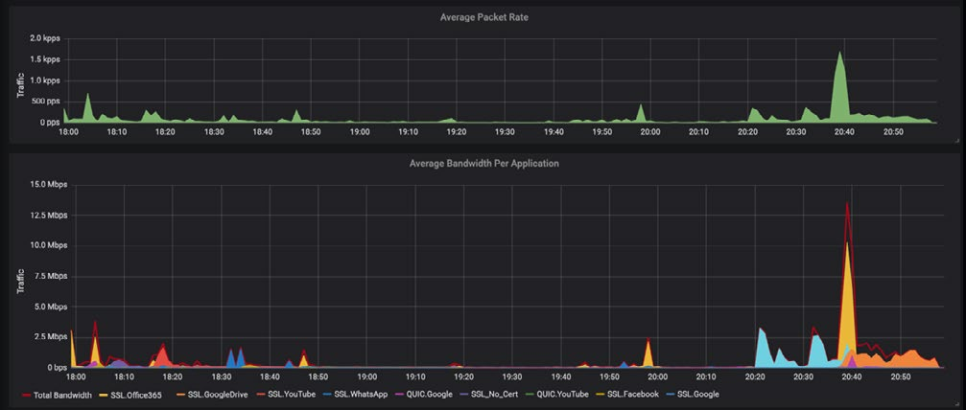
只需单击几下,他们就可以看到哪个用户正在将如此多的数据传输到365,以及多久执行一次。他们发现,每一个客户抱怨表现缓慢时,都会出现这种效果的高峰。
结论
使用这些仪表板可以使工程师指出问题的主要症状(数据包丢失和高延迟,是由网络拥塞引起的),从而将其引导到根本原因(有人不小心将其计算机配置为每小时对Microsoft 365进行一次完全备份!)
IOTA提供了正确的数据,正确的时间,与一个简单的工作流程,让工程师可以简单和远程访问的数据,解决网络问题。
尊敬的客户及合作伙伴:
感谢您长期以来对艾体宝的关注与支持!为提供更优质、稳定的服务体验,我们已完成官网的全面迁移升级,现正式启用全新平台。
新官网地址:https://www.itbigtec.com/
如您遇到任何访问或使用问题,请随时联系我们的技术支持团队:13533491614
感谢您的理解与配合!我们将持续优化产品与服务,期待为您创造更多价值。
艾体宝团队